Building with LLMs in Legal Tech: Current Uses, Hard Limits, and What’s Coming Next
You're the GC (or a practice group partner) and three vendors in one week pitch "AI-powered" contract review, "AI research," and "AI matter management"…

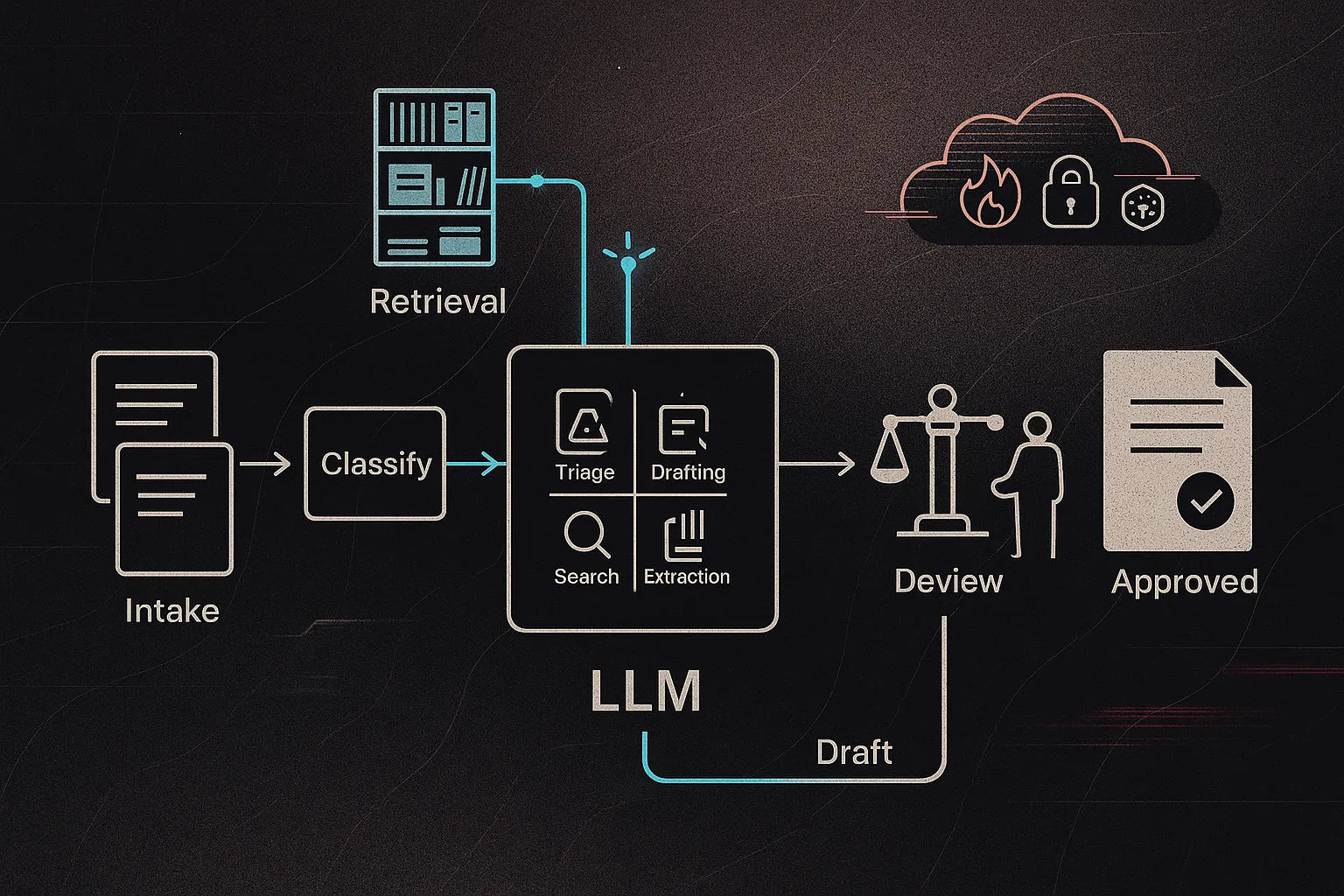
You’re the GC (or a practice group partner) and three vendors in one week pitch “AI-powered” contract review, “AI research,” and “AI matter management” — each with confident demos, none with clear answers on error rates, data handling, or what lawyers still must do. That gap between marketing and reality is where spend gets wasted, risk creeps in, and pilots fail from unmet expectations. LLMs are powerful, but only in certain shapes of legal work and only with the right architecture and review controls.
This article is a practical guide / checklist for legal teams and legal-tech builders on where LLMs help today, where they don’t, and how to plan for the next few years. (If you want an outcome-first framing, see Start with Outcomes — What ‘Good’ LLM Integration Looks Like in Legal.)
- Best fits today: first drafts, triage, extraction, and internal knowledge search — especially in high-volume, repeatable workflows.
- Hard limits: hallucinations, inconsistency, confidentiality constraints, and non-deterministic “reasoning” without verifiable sources.
- Design patterns that work: RAG (answer from your documents, with citations) and lawyer-in-the-loop checkpoints (see Lawyer in the Loop).
- Buy vs. build: evaluate tools by workflow impact, auditability, and governance — not model names.
- Next 3–6 months: pick one workflow, run a time-boxed pilot, measure error modes, and formalize data/security rules before scaling.
Start from Legal Outcomes, Not LLM Features
Legal teams often start with “we need an LLM” because vendors demo impressive text generation — but the business problem is usually throughput, consistency, or findability: faster NDA turns, more uniform advice notes, fewer escalations, or less time hunting for prior work. If you don’t define the outcome, you end up buying a feature (chat) instead of fixing a workflow.
- Decision: What judgment must be made faster/cheaper/more consistently (approve, escalate, redline, route)?
- Inputs: What governed sources exist (playbooks, clause libraries, prior matters, policies, approved templates)?
- Standard: What’s acceptable as a first draft vs. what requires lawyer sign-off and audit logs?
Example: Instead of comparing “AI contract review” tools by model quality, map your current contract-review workflow (intake → classify → flag issues → propose fallback language → lawyer review). Then test whether LLM building blocks (classification + draft markup + retrieval from your playbook) improve cycle time without increasing risk. For a deeper workflow framing, see Start with Outcomes and a concrete RAG workflow build in Creating a Chatbot for Your Firm — that Uses Your Own Docs.
Where LLMs Add Real Value in Legal Work Today
First-draft contract review and markup
Best pattern: give the model a structured playbook (approved positions + fallback language) and ask it to flag issues at the clause level, propose redlines, and explain why — then a lawyer decides. It’s strong for triage and first-pass markup, not for negotiation strategy or risk decisions.
Example: an NDA intake flow classifies the agreement (mutual/unilateral), assigns a risk tier, flags non-standard terms (term, confidentiality scope, residuals), and drafts fallback language for lawyer review (a defined lawyer-in-the-loop checkpoint).
Knowledge search across matters, precedents, and policies
RAG (retrieval-augmented generation) means the system first retrieves relevant internal documents, then answers using only those sources, ideally with citations. Think “internal research assistant” that surfaces prior memos and clauses instead of inventing internet-law answers. As collections grow, embeddings and sometimes knowledge graphs improve recall and de-duplication.
Drafting routine content and client communications
LLMs shine on repeatable outputs: compliance summaries, FAQs, client updates, matter-opening forms, and simple policy drafts — when paired with templates, version control, and approval workflows. Example: generate a jurisdiction-specific privacy notice from a maintained template library + a few parameters.
Workflow orchestration and document automation with LLMs as components
Most ROI comes from using LLMs inside end-to-end automations (intake → classify → route → draft → review). Example: an incident-reporting workflow where free-text is normalized into structured fields for compliance triage. See Embedding Tools Within Legal Workflows and Creating a Chatbot for Your Firm — that Uses Your Own Docs.
The Hard Limits of LLMs in Legal Practice (and When Not to Use Them)
Hallucinations and unverifiable reasoning
LLMs can confidently invent facts — e.g., citing a case that doesn’t exist or misquoting a holding. For legal research or advice, retrieval with citations (RAG) plus lawyer verification is non-negotiable; otherwise you’re auditing fluent text, not evidence.
Confidentiality, privilege, and data residency
Putting client data into consumer chat tools can create confidentiality and privilege headaches. Ask: Where is data stored? Is it used for training? What’s logged and for how long? Who can access prompts/outputs? Example: uploading sensitive M&A drafts to a public chatbot and later struggling to explain exposure in discovery.
Bias, consistency, and explainability
Outputs vary run-to-run and can mirror training-data bias. You’ll see it when two similar clauses get different “risk” labels with no stable rationale.
Cost, latency, and operational reliability
At scale, token costs and latency matter. Poorly scoped bulk review can produce runaway bills and timeouts.
When NOT to use an LLM
- Signing-ready work or final advice without lawyer-in-the-loop gates.
- Deterministic tasks better handled by rules/scripts (dates, math, validations).
- Highly sensitive/regulatory data without private deployment and governance.
Core Design Patterns for Safer, Useful LLM Integration in Legal Tech
Lawyer-in-the-loop as a system, not a slogan
“Lawyer-in-the-loop” only works when it’s designed as explicit checkpoints: (1) lawyers approve what goes in (data scope, redaction, playbook), (2) lawyers review what goes out (client-facing drafts, filings, advice), and (3) lawyers maintain the playbook over time. Compare a contract-review flow where the model proposes redlines but cannot send them until a reviewer approves, versus auto-accepting vendor suggestions. See What Is Lawyer-in-the-Loop?.
Retrieval-Augmented Generation (RAG) over your own documents
RAG beats “ask GPT” for most legal work because it grounds answers in your sources. The simple loop: index your memos/policies → retrieve relevant passages → answer with citations. Example: an employment-law FAQ bot limited to firm memos and local statutes. Vector databases help semantic retrieval; knowledge graphs help when relationships and entities matter.
Guardrails through prompts, templates, and validation
Treat prompts as policy: jurisdiction, role, risk appetite, tone, and citation rules. Add fail-safe instructions (“If you can’t support it, say ‘I don’t know’”). Then validate outputs: schema checks (JSON), banned terms, citation-required rules, and confidence thresholds before anything is saved or sent.
Choosing between vendor APIs and private/open-source models
Hosted APIs are fastest to ship and often highest quality, but raise control and lock-in issues. Private/open-source hosting increases control and customization, but adds MLOps burden. Example: a small firm pilots with an enterprise API + strict data controls; a legal-tech vendor with IP and latency needs hosts in-house. For an accessible starting point, see Hugging Face Spaces for Lawyers: A Beginner’s Guide.
Evaluating and Buying Legal AI Tools Built on LLMs
Vendor claims like “AI-powered,” “trained on millions of contracts,” or “98% accuracy” are rarely comparable because they hide the task definition, the test set, and what counts as an “error.” Buy against workflow outcomes and governance, not model branding.
- Task clarity: What exact steps are assisted (triage, extraction, redline suggestions, Q&A)?
- Data scope: Does it use your documents/playbooks (RAG) or generic training?
- LIT design: Where are review gates, and what can/can’t be sent without approval? (See What is Lawyer-in-the-Loop?.)
- Error modes: How are hallucinations, missing citations, and low-confidence outputs flagged?
- Data protection: storage location, training use, retention/logging, sub-processors, access controls.
- Auditability: logs, versioning of prompts/playbooks, replay of decisions, export of data.
Mini-case: Firm A buys a generic “AI contract review” tool and sees inconsistent outputs and low adoption. Firm B pilots an NDA workflow tool with a clear playbook and mandatory reviewer sign-off — and it sticks.
Run a 4–8 week pilot with baseline metrics (cycle time, lawyer override rate, critical-error rate, satisfaction) before scaling.
Planning Your LLM Integration Roadmap for the Next 12–24 Months
Start with one or two high-leverage workflows
Pick workflows like NDAs/routine contracts, internal knowledge Q&A, or policy drafting. Prioritize where volume is high, inputs are somewhat standardized, draft-level output is acceptable, and you can measure impact (cycle time, escalations, rework).
Build data and governance foundations early
LLMs don’t fix messy systems. Invest early in document hygiene, playbooks, tagging, retention rules, an AI usage policy, and vendor addenda (data use, logging, audit). This is a cross-functional effort: legal + IT/security + ops (+ product for vendors). See AI & Tech Governance.
Iterate from pilot to production
Use a simple lifecycle: discovery → prototype → controlled pilot → refinement → scaled deployment. Example: an internal NDA assistant becomes a firm-wide service once review gates, playbook updates, and training are documented.
Watch the frontier without chasing hype
Expect better small models, multimodal inputs (docs + images), and improved monitoring/evals. Schedule quarterly stack reviews and benchmark new models on your own test set; avoid full rewrites every six months. For workflow integration patterns, see Embedding Tools Within Legal Workflows.
FAQs on LLMs in Legal Technology
Q1: Can LLMs replace junior lawyers or paralegals? They can replace chunks of drafting, summarizing, extraction, and triage, but not judgment-heavy work: issue-spotting in novel fact patterns, client counseling, ethics calls, and owning the final product.
Q2: Is it ever safe to put client data into public LLM tools? Treat consumer chatbots as unsafe by default. If you must, use an enterprise offering with clear terms on retention, training use, and access controls, and follow a written policy (see AI & Tech Governance).
Q3: How accurate are LLM-based legal tools in practice? Accuracy depends on the task, your documents, and how the system is evaluated. Require firm-specific testing on real samples, and track critical-error rates — not just “helpful” outputs.
Q4: What skills should lawyers and legal ops develop? Workflow thinking, basic prompt design, and the fundamentals of RAG and lawyer-in-the-loop controls (start with What is Lawyer in the Loop?).
Q5: How do LLMs interact with document automation and KM? They complement them: templates/macros handle deterministic drafting; LLMs handle messy inputs and first drafts. The best systems route work between both, with version control and review gates.
Actionable Next Steps
- Map one high-volume workflow (e.g., NDAs or research memos) and capture baseline pain points: cycle time, handoffs, and recurring error types.
- Choose your deployment path: a hosted LLM pilot with strict controls, or groundwork for a more private model/architecture.
- Design lawyer-in-the-loop checkpoints (inputs approved, outputs gated, playbook ownership assigned). Start with What is Lawyer-in-the-Loop?.
- Update governance: AI usage policy + vendor due diligence language (training use, retention/logging, sub-processors, audit rights). See AI & Tech Governance.
- Run a 4–8 week pilot with success metrics (cycle time, critical-error rate, lawyer override rate, satisfaction), then decide to scale, adjust, or stop.
- Appoint 2–3 internal champions (legal, ops, security) and give them protected time to test and document learnings.
If you want help designing an LLM-assisted workflow, evaluating tools, or building governance that fits real legal practice, contact Promise Legal.